반응형
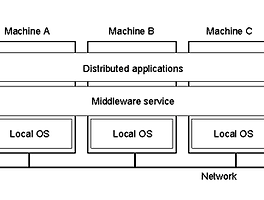
Massively Distributed Database System이란?
Distributed Database는 다음과 같은 역할을 해야 한다.
- Data Dictionary 관리 : 어디에 데이터가 어떻게 저장되어있는지 관리해야 함
- 스키마, 쿼리, DBMS의 Heterogeneity를 해결해야 함
- 안전성과 일관성을 유지해야 함
- 사용자로 하여금 하나의 DB처럼 보이게 해야 함 : transparency
- 유동적으로 load를 balancing 해야 함
- 쿼리를 최적화 해야 함
데이터베이스를 구성하는 3가지 Layer

- External Layer : 사용자가 Database를 이해하기 쉽도록 View를 정의
- Conceptual Layer : View에 맞는 개념적인 스키마를 정의
- Physical Layer : 실제 데이터가 저장되는 포맷

- Distributed Database System에서는 Global하지만 똑 같은 계층을 유지함
- Blocking Factor : 여러 개의 이기종 데이터베이스를 관리하다보면 제약조건을 두게 되는데 이 제약조건을 Blocking factor라고 함. 많을수록 성능은 좋아지지만 관리가 어려움
- View를 구현하는 기법 중에 view materialization이라는 기법이 있는데 이것은 view를 위한 물리적인 테이블을 새로 만들어서 논리적인 테이블로 구성된 것보다 속도를 더 높이는 기법임
Distributed Database System에서의 이슈
- Replication vs Partitioning : 어떻게 replication하고 Partitioning 해야 하는가
- Distributed DBMS : 서로 다른 DBMS를 어떻게 관리해야 할까?
- Transparency : 여러 개의 DB가 하나처럼 보여야 함
- Query Optimization : Query 조합이 복잡하기 때문에 cost 낮은 쪽으로 optimization 해야 함
- Transaction Management : consistency를 유지해야 함, 여러 DB에 분산되어 있는 정보가 일관성을 유지해야 함
Replication
- 자신이 가지고 있는 데이터를 다른 DB에 복제해서 중복으로 저장을 하고 있는 것을 Replication이라고 함
- Replication의 장점은 퍼포먼스가 높아진다는 것이 있지만, consistency를 위한 update handling이 어려움
- Snapshot replication : 중앙 서버가 업데이트 로그를 가지고 있다가 일정 주기로 모두 동시에 update하는 기법으로 consistency를 유지할 수 있지만, 주기 사이에는 data consistency가 이뤄지지 않음. 주기 동안에도 데이터가 또 변할 수 있다는 말인 것 같음. 또한 업데이트시 대량의 네트워크 트레픽을 유발할 수 있기 때문에 Communication overhead가 발생할 수 있음.
- Near Real-Time replication : 말그대로 실시간으로 업데이트 요청이 있을 때마다 바로바로 다른 DB에 업데이트를 수행하는 것. 내 생각에는 이런 방식을 사용한다면 transaction이 많아져서 퍼포먼스가 많이 떨어질 것 같음
- Pull Replication : 중앙에서 push 프로토콜로 업데이트를 하는게 아니라 각 DB에서 필요할 때마다 중앙서버로 update할 게 있는지 물어보고 업데이트를 수행하는 것. 이것은 consistency 유지가 어려울 것 같은데?
- 가장 좋은 것은 Synchronized Replication : 신뢰성, 확장성, communication overhead가 적고, consistency, manageability 함
다음과 같은 Update Handling 기법이 있음
- 이 밖에도 exclusive ownership vs shared ownership, 동기적 업데이트 vs 비동기적 업데이트, simple snapshot vs multiple snapshot 의 이슈들이 있음
Partitioning
- Replication이 데이터들을 여러 곳에 복제해서 퍼포먼스를 높였다면, Partitioning은 데이터를 효율적으로 여러 DB에 저장해서 공간적인 제약을 극복함. 또한 이렇게 하면 확장성을 높일 수 있는데, 새로운 DB가 들어와도 그 DB의 Design을 바꾸지 않아도 필요한 데이터를 얻을 수 있음
- 하지만, 각각 다른 Query language를 가지는 DB에서 데이터를 가져와야 하기 때문에 Communication Overhead가 약간 높아질 수 있고 그렇기 때문에 DB를 관리하거나 consistency를 유지하는게 매우 어려움
- Partitioning을 위해서는 테이블을 분리해야 하는데, 효율성, Local Optimization, Communication Overhead, Security 등을 고려해야 함
반응형
'IT 기술 > 용어 및 개념' 카테고리의 다른 글
| REST API (0) | 2015.09.16 |
|---|---|
| Massively Distributed Database Systems(Transaction Management) (0) | 2014.04.23 |
| Distributed System 기초 (0) | 2014.04.22 |
| 핵티비즘(Hacktivism) (0) | 2012.03.05 |
| DHCP (0) | 2012.01.25 |